bert-as-service Documentation¶
bert-as-service is a sentence encoding service for mapping a variable-length sentence to a fixed-length vector.
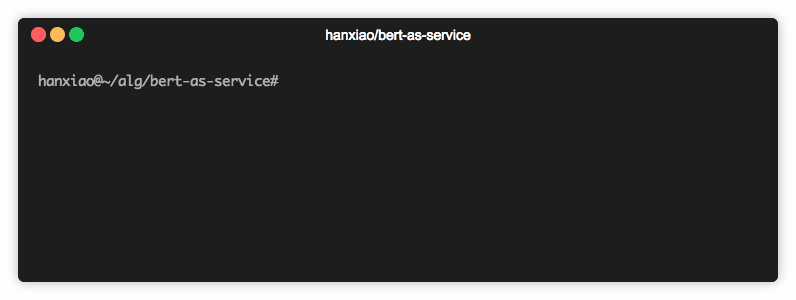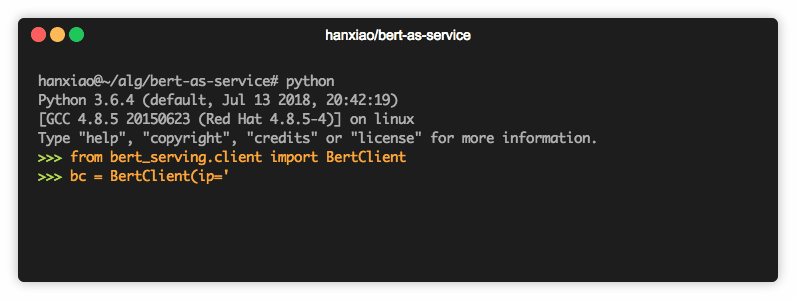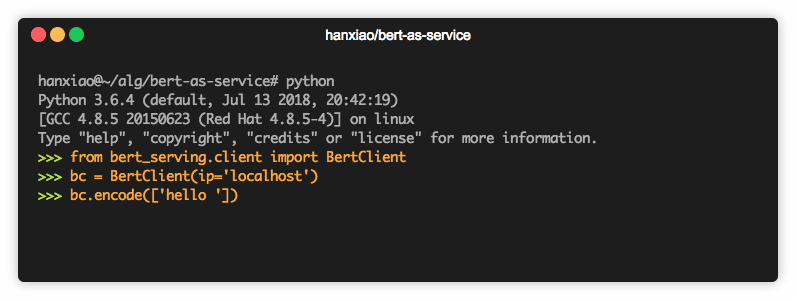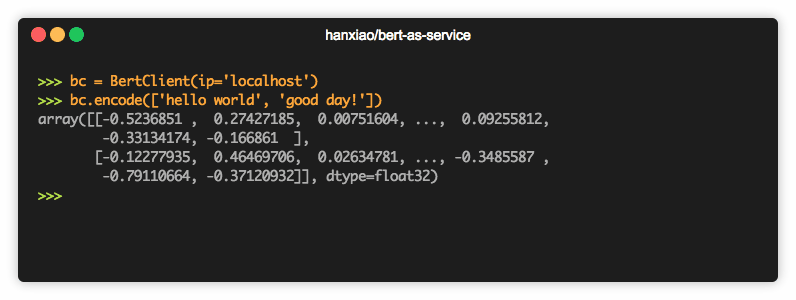
Installation¶
The best way to install the bert-as-service is via pip. Note that the server and client can be installed separately or even on different machines:
pip install -U bert-serving-server bert-serving-client
Note
The server MUST be running on Python >= 3.5 with Tensorflow >= 1.10 (one-point-ten). Again, the server does not support Python 2!
Note
The client can be running on both Python 2 and 3.
Table of Content¶
- What is it
- Getting Start
- Tutorials
- Building a QA semantic search engine in 3 minutes
- Serving a fine-tuned BERT model
- Getting ELMo-like contextual word embedding
- Using your own tokenizer
- Using BertClient with
tf.dataAPI - Training a text classifier using BERT features and
tf.estimatorAPI - Saving and loading with TFRecord data
- Asynchronous encoding
- Broadcasting to multiple clients
- Monitoring the service status in a dashboard
- Using
bert-as-serviceto serve HTTP requests in JSON
- Using BertClient
- Using BertServer
- Frequently Asked Questions
- Where is the BERT code come from?
- How large is a sentence vector?
- How do you get the fixed representation? Did you do pooling or something?
- Are you suggesting using BERT without fine-tuning?
- Can I get a concatenation of several layers instead of a single layer ?
- What are the available pooling strategies?
- Why not use the hidden state of the first token as default strategy, i.e. the
[CLS]? - BERT has 12/24 layers, so which layer are you talking about?
- Why not the last hidden layer? Why second-to-last?
- So which layer and which pooling strategy is the best?
- Could I use other pooling techniques?
- Can I start multiple clients and send requests to one server simultaneously?
- How many requests can one service handle concurrently?
- So one request means one sentence?
- How about the speed? Is it fast enough for production?
- Did you benchmark the efficiency?
- What is backend based on?
- What is the parallel processing model behind the scene?
- Why does the server need two ports?
- Do I need Tensorflow on the client side?
- Can I use multilingual BERT model provided by Google?
- Can I use my own fine-tuned BERT model?
- Can I run it in python 2?
- Do I need to do segmentation for Chinese?
- Why my (English) word is tokenized to
##something? - Can I use my own tokenizer?
- I encounter
zmq.error.ZMQError: Operation cannot be accomplished in current statewhen usingBertClient, what should I do? - After running the server, I have several garbage
tmpXXXXfolders. How can I change this behavior ? - The cosine similarity of two sentence vectors is unreasonably high (e.g. always > 0.8), what’s wrong?
- I’m getting bad performance, what should I do?
- Can I run the server side on CPU-only machine?
- How can I choose
num_worker? - Can I specify which GPU to use?
- Benchmark